[사진=쏘카]
쏘카는 오는 5일 ICLR(International Conference on Learning Representations)에서 운영하는 워크숍 PML4DC(Practical Machine Learning for Developing Countries)에 참석해 딥러닝 연구 논문을 발표한다. 데이터 리소스가 부족한 환경에서 효율적으로 데이터를 학습할 수 있는 사례를 소개한다.
쏘카 AI팀은 '공개 의도 분류에 대한 보정 효과 분석(Uncovering Effectiveness of Calibration on Open Intent Classification)'에 대한 논문을 발표한다. 논문에서는 딥러닝 모델이 실제값과 예측값의 차이를 계산하는 크로스 엔트로피 손실(Cross Entropy Loss)로 데이터를 학습할 경우 생기는 손실값(loss)에 보정(calibration)을 추가하는 방법을 제안한다.
또 문장 분류 문제에서 기존 학습 데이터에 포함되지 않은 카테고리 문장이 주어지는 상황에서 딥러닝 모델이 이를 별도의 OOD(out-of-distribution)의 라벨로 분류하는 방법과 데이터셋이 적은 환경에서 문장 분류 문제를 효과적으로 풀어낸 수 있는 방법을 담았다.
쏘카는 이러한 연구 성과 등을 토대로 플랫폼 운영 효율 개선에 박차를 가하고 있다. 플랫폼 운영을 통해 얻은 자연어 데이터를 토대로 쏘카 도메인을 가장 잘 이해할 수 있는 인공지능(AI) 모델도 개발하고 있다. 이르면 연내 해당 AI 모델을 기반으로 한 AI 고객센터 솔루션을 도입할 계획이다.
이를 위해 쏘카는 거대언어모델을 자체적으로 연구·개발해 대화형 AI를 구축하고 있다. 대화형 AI는 고객의 발화 의도를 이해하고 이에 적합한 응답을 생성해 차량 이용 중 발생하는 문의에 신속하고 정확하게 응대할 수 있다. 또 쏘카가 자체 연구개발한 STT(Speech-to-Text) 기술을 통해 고객과 상담사 사이의 통화 내용을 텍스트 처리하고, 고객 질의 내용을 분석해 서비스를 개선할 수 있을 것으로 기대하고 있다.
이번 논문에 참여한 쏘카 AI팀은 "세계 최고 권위 학회에서 쏘카의 딥러닝 연구 성과를 공유할 수 있는 좋은 기회"라며 "이번 연구를 발판 삼아 쏘카에서 발생할 수 있는 다양한 문제를 데이터와 기술을 활용해 해결하고 효율화할 수 있는 방안을 연구해 나가겠다"고 말했다.




![[IFA 2024] 삼성, 獨 전역 스마트싱스 체험존 운영...이동형 스마트홈 유럽에 알려](https://image.ajunews.com/content/image/2024/09/07/20240907161523517458_388_136.jpg)




![[포토] 9월인데도 덥다. 제주 바다로!](https://image.ajunews.com/content/image/2024/09/07/20240907222954590286_518_323.jpg)
![[포토] 윤석열 대통령, 기시다 후미오 일본 총리와 소인수 회담](https://image.ajunews.com/content/image/2024/09/06/20240906230059805064_518_323.jpg)
![[포토] 한일 정상회담 앞둔 기시다 일본 총리 도착](https://image.ajunews.com/content/image/2024/09/06/20240906142402606796_518_323.jpg)
![[포토] 팔레스타인전 보는 정몽규 회장](https://image.ajunews.com/content/image/2024/09/06/20240906000236657389_518_323.jpg)
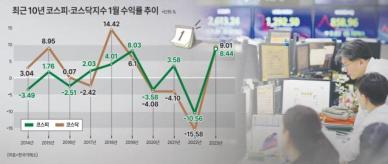
![[금투세 폐지 논란] 코리아 디스카운트 심화...韓증시 불확실성 높여](https://image.ajunews.com/content/image/2024/01/03/20240103150426112900_388_136.jpg)