
아담 셀립스키 AWS 최고경영자가 29일(현지시간) 미국 라스베이거스 AWS 리인벤트 2022 2일차 키노트를 통해 HPC 워크로드용 아마존 EC2 인스턴스를 소개하고 있다. [사진=임민철 기자]
아마존웹서비스(AWS)가 자체 설계한 반도체 프로세서로 고성능컴퓨팅(HPC), 네트워크 집약적 애플리케이션, 머신러닝 추론 연산 구동 성능을 확 끌어올린 가상서버 신상품 3종을 선보였다. 전날 소프트웨어 알고리즘으로 머신러닝 훈련 연산 성능을 높인 신상품과 함께 주요 HPC와 인공지능(AI) 모델 제작과 활용을 위해 효율을 높인 인프라를 지원하게 됐다.
AWS는 29일(현지시간) 미국 라스베이거스 AWS 리인벤트 2022 현장에서 'Hpc7g', 'C7gn', 'Inf2' 등 새로운 세 가지 아마존 EC2 인스턴스를 공개하고 이들이 더 낮은 비용으로 더 높은 성능을 제공한다고 밝혔다.
아스트라제네카, 포뮬러원(Formula 1), 맥사테크놀로지스 등이 유전체학 처리, 전산유체역학, 일기예보 시뮬레이션 등 기존 HPC 워크로드를 AWS에서 실행하고 있다. 엔지니어, 연구원, 과학자가 코어 수천 개로 데이터를 처리하고 거의 무제한 컴퓨팅 용량과 고대역폭 네트워크를 제공하는 HPC에 최적화한 아마존 EC2 인스턴스로 HPC 워크로드를 실행한다.
AWS에 따르면 Hpc6a, Hpc6id, C5n, R5n, M5n, C6gn 등 기존 HPC용 인스턴스는 대부분 HPC 사용 사례에 충분하지만, 고객들은 AI나 자율주행차 등 새로운 애플리케이션 문제를 해결하고 코어를 수만 개 이상으로 확장하는 HPC 워크로드 비용을 줄이기 위해 추가로 확장할 수 있는 HPC 최적화 인스턴스를 원한다.
AWS는 "Hpc7g 인스턴스는 모든 AWS 인스턴스 유형에서 높은 메모리 대역폭과 CPU당 가장 높은 네트워크 대역폭을 제공하므로 HPC 애플리케이션 결과를 더 빨리 낸다"며 "고객은 오픈소스 클러스터 관리 도구인 AWS 패러렐클러스터(ParallelCluster)와 함께 Hpc7g 인스턴스를 사용해 다른 인스턴스 유형과 Hpc7g 인스턴스를 프로비저닝할 수 있다"고 설명했다.

셀립스키 CEO가 그래비톤3 칩을 구동하는 C7gn 인스턴스를 소개하고 있다. [사진=임민철 기자]
C7gn 인스턴스는 신형 니트로(Nitro) 카드를 탑재한 네트워크 집약적 워크로드용 인스턴스로 기존 인스턴스 대비 CPU당 네트워크 대역폭을 2배로 늘리고 초당 패킷 성능을 3배 늘렸다. 방화벽, 가상 라우터, 로드 밸런서 등 네트워크 가상 어플라이언스나 데이터 암호화같이 까다로운 네트워크 집약적 워크로드를 실행하는 데 알맞다.
AWS는 아마존 EC2 네트워크 최적화 인스턴스 가운데 C7gn 인스턴스가 최고 수준 대역폭과 패킷 처리 성능을 제공하고 '엘라스틱 패브릭 어댑터(EFA)' 네트워크 지연시간을 줄일 수 있으며 기존 C6gn 인스턴스 대비 암호화 워크로드보다 25% 높은 연산 성능과 2배 빠른 속도를 지원한다고 설명했다.
C7gn 인스턴스의 고성능과 빠른 네트워크 속도를 실현하는 니트로 카드는 네트워크 가속 기능을 지닌 '니트로 AL10' 칩으로 구동된다. 이 니트로 카드는 호스트 CPU에서 특수 하드웨어로 기능 입출력을 오프로드하고 가속화해 대다수 아마존 EC2 인스턴스 자원의 CPU 사용률을 낮추면서 일관된 성능을 제공한다.
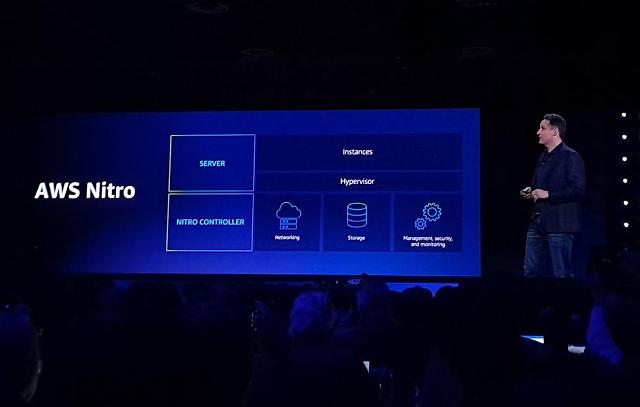
셀립스키 CEO가 자체 개발한 하드웨어 니트로(Nitro)를 소개하고 있다. [사진=임민철 기자]
Inf2 인스턴스는 머신러닝 추론 연산에 특화한 신형 프로세서 '인퍼런시아2(Inferentia2)'로 구동되는 가상서버다. 최대 1750억개 파라미터를 다루는 딥러닝 모델을 실행한다. 기존 Inf1 인스턴스 대비 4배 처리 성능, 10분의1 수준의 짧은 지연시간을 구현한다.
2019년 Inf1 출시 당시 딥러닝 모델 파라미터는 수백만 개였지만 이후 전반적인 딥러닝 모델 크기와 복잡성은 훨씬 커졌다. 파라미터 1000억개 이상을 포함한 대규모 언어 모델은 널리 보급되는 가운데 대규모 데이터 훈련으로 연산 요구 사항이 증가하는 추세다. 더 나은 애플리케이션과 더욱 맞춤화된 경험에 대한 요구를 수용하기 위해 데이터 사이언티스트와 머신러닝 엔지니어가 더 크고 복잡한 딥 러닝 모델을 구축하고 있다.
AWS는 머신러닝 복잡성과 비용 관점에서 비중이 큰 추론 영역이 고객 혁신을 늦출 수 있다고 보고 Inf2 인스턴스로 대규모 딥러닝 기술을 사용한 차세대 애플리케이션을 다루는 고객에게 추론 작업에 유연한 소프트웨어, 짧은 지연 시간, 높은 처리 성능을 제공한다. 최초로 대규모 모델 추론을 여러 칩에 분산 처리하고 추론당 전력을 줄이는 CFP8과 정밀도가 낮은 데이터 유형을 활용하지 않은 모듈 성능을 높이는 FP32 등 다양한 데이터 유형을 지원한다.
고객은 머신러닝 추론 통합 소프트웨어 개발 도구인 AWS 뉴런(AWS Neuron)을 사용해 Inf2 인스턴스를 시작할 수 있다. AWS 뉴런은 파이토치, 텐서플로 등 머신러닝 프레임워크와 통합돼 최소 코드 변경으로 기존 모델을 Inf2 인스턴스에 배포하도록 지원한다. 초당 192GB 링(ring) 연결을 제공하는 AWS 인스턴스 인터커넥트 '뉴런링크'를 지원한다.

셀립스키 CEO [사진=임민철 기자]
AWS는 지난 10년 간 클라우드에서 저 더렴한 비용으로 성능과 확장성을 제공하기 위해 자체 칩을 설계하고 이를 활용하는 가상서버 상품군을 확대해 왔다. 2013년 AWS 니트로 시스템을 도입한 이후 니트로 시스템 5세대, 그래비톤 칩 3세대, 추론용 인퍼런시아 칩 2세대, 머신러닝 훈련용 트레이니엄 칩 등을 개발했다.
AWS는 클라우드 기반으로 반도체 회로설계와 오류검증을 자동화한 '전자 설계 자동화(EDA)' 도구를 사용해 칩을 더 빠르게 개발하고 제공한다. 이를 탑재한 아마존 EC2 인스턴스의 성능, 비용, 전력 효율성을 개선해 고객 요구사항에 최적화한 칩과 인스턴스 조합을 선보이고 있다.
데이비드 브라운(David Brown) AWS 아마존 EC2 담당 부사장은 "그래비톤에서 트레이니엄과 인퍼런시아 칩, 니트로 카드에 이르기까지 AWS 자체 설계 실리콘 각 세대는 다양한 고객 워크로드에 향상된 수준의 성능, 저렴한 비용, 전력 효율성을 제공한다"며 "오늘 새로 공개한 인스턴스는 HPC, 네트워크 집약, 머신러닝 추론 워크로드 성능을 개선해 고객 선택지를 확대했다"고 말했다.
전날(28일) AWS 리인벤트 2022 1일차 키노트를 진행한 피터 데산티스 AWS 유틸리티컴퓨팅 수석부사장도 AWS 클라우드 인프라의 HPC와 AI 구동 성능을 높인 자체 하드웨어 기술력을 강조했다. 그는 기존 머신러닝 훈련 연산 전용 반도체 칩 '트레이니엄'을 구동하는 신형 인스턴스 'Trn1n'을 제공한다고 밝혔다.
C7gn과 Hpc7g처럼 새로운 칩을 탑재한 것은 아니지만, Trn1n은 확률적 반올림과 메모리 공유 최적화 알고리즘으로 모델 훈련 속도를 끌어올린 인스턴스로 소개됐다.








![[포토] 탄핵 찬성 입장 공식화한 김재섭 의원](https://image.ajunews.com/content/image/2024/12/11/20241211133540832306_518_323.jpg)
![[포토] 노벨문학상 수상한 한강 작가](https://image.ajunews.com/content/image/2024/12/11/20241211095128511160_518_323.jpg)
![[포토] 사상 초유 감액 예산안 국회 본회의 통과](https://image.ajunews.com/content/image/2024/12/10/20241210174015528552_518_323.jpg)
![[포토] 눈시울 붉히는 707특수임무단장](https://image.ajunews.com/content/image/2024/12/09/20241209092346845300_518_323.jpg)


