거대언어모델은 매우 방대한 데이터를 학습했기 때문에 학습에 사용된 바 없는 데이터를 바탕으로 답변할 때나 오래 전 데이터를 바탕으로 답변하는 등 문제점들이 지적돼 왔다. 이런 문제들을 해결하기 위해 거대언어모델이 학습된 내용만으로 답변하는 것 대신, 데이터베이스를 검색해 답변을 생성하는 검색증강생성(RAG) 기술이 최근 각광받고 있다. 나아가 사용자의 질문이 복잡할 경우 다양한 검색 결과를 바탕으로 추가 정보를 다시 검색해 적절한 답변을 생성할 때까지 반복하는 반복적 RAG(IterativeRAG)라는 기술이 개발됐으며, 이는 현재까지 개발된 가장 최신 기술이다.
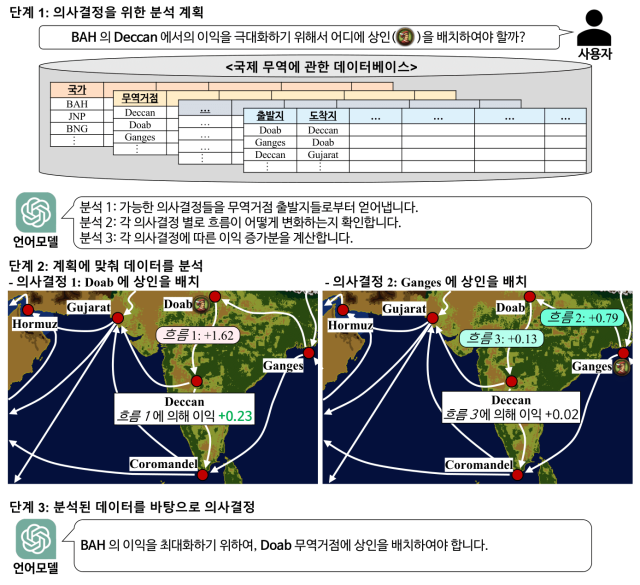
연구팀은 기업 의사결정 문제가 GPT-3.5 터보에서 반복적 RAG 기술을 사용하더라도 정답률이 10% 미만에 이르는 고난도 문제임을 보이고, 이를 해결하기 위해 반복적 RAG 기술을 한층 더 발전시킨 계획RAG 기술을 개발했다. 계획 RAG는 기존 RAG 기술들과 다르게 주어진 의사결정 문제, 데이터베이스, 비즈니스 규칙을 바탕으로 어떤 데이터 분석이 필요한지에 대한 거시적 차원의 계획(plan)을 먼저 생성한 후, 그 계획에 따라 반복적 RAG를 이용해 미시적 차원의 분석을 수행한다.
이는 마치 기업의 의사결정권자가 어떤 데이터 분석이 필요한지 계획을 세우면, 그 계획에 따라 데이터 분석팀이 데이터베이스 솔루션들을 이용해 분석하는 형태와 유사하다는 설명이다. 다만 이러한 과정을 모두 사람이 아닌 거대언어모델이 수행한다. 계획 RAG 기술은 계획에 따른 데이터 분석 결과로 적절한 답변을 도출하지 못하면, 다시 계획을 수립하고 데이터 분석을 수행하는 과정을 반복한다.
김민수 교수는 "기존 반복적 RAG에 비해 계획 RAG가 의사결정 정답률을 최대 32.5% 개선함을 보였다"면서 "이를 통해 기업들이 복잡한 비즈니스 상황에서 최적의 의사결정을 사람이 아닌 거대언어모델을 이용하여 내리는데 적용되기를 기대한다"고 말했다.







![[날씨] 아침 기온 0도 안팎 뚝…일교차 15도 내외](https://image.ajunews.com/content/image/2024/11/23/20241123161702152439_388_136.jpg)
![[슬라이드 포토] 성수동이 들썩 오데마 피게 포토콜 참석한 스타들](https://image.ajunews.com/content/image/2024/11/22/20241122205657914816_518_323.jpg)
![[포토] 제8회 서민금융포럼](https://image.ajunews.com/content/image/2024/11/21/20241121114536531007_518_323.jpg)
![[포토] 기조연설 하는 페이커 이상혁](https://image.ajunews.com/content/image/2024/11/20/20241120115246771576_518_323.jpg)
![[포토] 발왕산은 벌써 겨울](https://image.ajunews.com/content/image/2024/11/19/20241119205226273772_518_323.jpg)


