
아래아한글 2018년 버전에서 '안중근'이나 '이봉창'을 곧바로 한자변환할 수가 없었다. [사진=강효백 교수 제공]
한글과컴퓨터(이하 한컴)가 개발한 국내 대표 문서작성 프로그램 ‘아래아한글’에 ‘안중근’ ‘고려’ 등 국내 주요 고유명사와 인명이 한자로 변환되지 않았던 문제가 해결됐다.
본지는 지난해 1월 ‘[강효백 칼럼] "사라진 高麗, 安重根…" 아래한글은 ‘일본 아래한글’ 인가?(22일자)’ 제하의 기사를 통해 아래아한글에 일본식 용어는 한자변환이 잘되는 반면, 국내 주요 고유명사가 누락된 점을 지적한 바 있다.
당시 자사의 강효백 논설위원(경희대 법무대학원 교수)은 아래아한글 2018 버전을 사용하던 중 △고려 △안중근 △윤봉길 △전봉준 △김좌진 등 국내 주요 고유명사와 애국지사명이 한자로 변환되지 않는 것을 발견했다.
안중근의 경우 ‘안중(安中)’으로 따로 인식하고, 한국의 한문 표기인 ‘韓國’은 5개 단어 중에 가장 끝에 위치했다. 반면 일본과 관련된 단어를 한자로 변환하면 단독으로 나오거나 가장 앞단에 나왔다.
강 위원은 "을사보호조약, 한일합병조약, 한일합방, 황국, 신민, 내선일체 등 일본식 용어는 한자변환되나 을사늑약, 한일병탄, 일제침략, 불령선인은 안 된다"며 "한국의 고유명사들이 변환되지 않고 있으나 우리가 거의 모르거나 소수의 전문가만이 쓸 만한 일본의 고유명사는 변환된다"고 꼬집었다.
강 위원은 한컴 측에 즉각 시정을 요구했다. 한컴은 본지의 문제 제기 이후 약 6개월 만인 지난해 7월 31일 한자변환 기능 업데이트를 단행했다. 아래아한글 전 버전의 한자사전과 인명사전에 누락된 데이터를 복원했다. 특히 2018년 제품에선 두 사전을 통합해 사용 편의성도 높였다.
한컴 측은 “지난해 1월 칼럼을 통해 이 같은 문제를 인지했다”며 “2013년 14만여 단어의 한자 데이터를 추가 및 통합하는 과정에서 총 1218개의 데이터가 유실됐다”고 설명했다.
이어 “한컴은 사전 데이터를 특정 기관에서만 수급받고 있지 않으며 여러 기관, 단체들과 협력해 수시로 데이터 수급 및 검수를 받고 있다”며 “유사현상들이 더 이상 발생하지 않도록 경희대학교와 산학연을 체결해 약 32만 개의 한자 데이터에 대해 전체 검수를 진행하고 있다”고 덧붙였다.
끝으로 "의도적으로 일본식 한자와 국내 한자를 구분해서 일본식 한자만 변환되게 설정했다는 주장은 사실이 아니다"라고 강조했다.
본지는 지난해 1월 ‘[강효백 칼럼] "사라진 高麗, 安重根…" 아래한글은 ‘일본 아래한글’ 인가?(22일자)’ 제하의 기사를 통해 아래아한글에 일본식 용어는 한자변환이 잘되는 반면, 국내 주요 고유명사가 누락된 점을 지적한 바 있다.
당시 자사의 강효백 논설위원(경희대 법무대학원 교수)은 아래아한글 2018 버전을 사용하던 중 △고려 △안중근 △윤봉길 △전봉준 △김좌진 등 국내 주요 고유명사와 애국지사명이 한자로 변환되지 않는 것을 발견했다.
안중근의 경우 ‘안중(安中)’으로 따로 인식하고, 한국의 한문 표기인 ‘韓國’은 5개 단어 중에 가장 끝에 위치했다. 반면 일본과 관련된 단어를 한자로 변환하면 단독으로 나오거나 가장 앞단에 나왔다.
강 위원은 한컴 측에 즉각 시정을 요구했다. 한컴은 본지의 문제 제기 이후 약 6개월 만인 지난해 7월 31일 한자변환 기능 업데이트를 단행했다. 아래아한글 전 버전의 한자사전과 인명사전에 누락된 데이터를 복원했다. 특히 2018년 제품에선 두 사전을 통합해 사용 편의성도 높였다.
한컴 측은 “지난해 1월 칼럼을 통해 이 같은 문제를 인지했다”며 “2013년 14만여 단어의 한자 데이터를 추가 및 통합하는 과정에서 총 1218개의 데이터가 유실됐다”고 설명했다.
이어 “한컴은 사전 데이터를 특정 기관에서만 수급받고 있지 않으며 여러 기관, 단체들과 협력해 수시로 데이터 수급 및 검수를 받고 있다”며 “유사현상들이 더 이상 발생하지 않도록 경희대학교와 산학연을 체결해 약 32만 개의 한자 데이터에 대해 전체 검수를 진행하고 있다”고 덧붙였다.
끝으로 "의도적으로 일본식 한자와 국내 한자를 구분해서 일본식 한자만 변환되게 설정했다는 주장은 사실이 아니다"라고 강조했다.
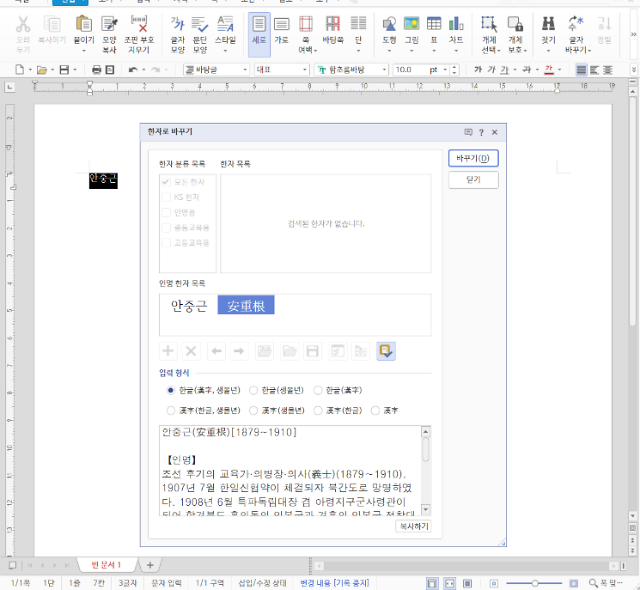
본지 지적으로 개선된 아래아한글 2018 한자변환[사진=한글과컴퓨터]








![[포토] 우원식 의장에게 항의하는 국민의힘](https://image.ajunews.com/content/image/2024/12/27/20241227165203327755_518_323.jpg)
![[포토] 본회의장 나와 규탄대회 연 국민의힘](https://image.ajunews.com/content/image/2024/12/27/20241227165050901400_518_323.jpg)
![[포토] 헌법재판소 심판정 나서는 배진한 변호사](https://image.ajunews.com/content/image/2024/12/27/20241227165355871140_518_323.jpg)
![[포토] 다이빙 신임 주한 中대사, 전략적 협력 동반자관계 발전시킬 것](https://image.ajunews.com/content/image/2024/12/27/20241227140309624240_518_323.jpg)


